Abstract and Introduction-
Machine Learning is tied in with building programs with tunable parameters that are maintained and balanced in order to improve and enhance their conduct by managing to the recently observed information.
Learning of machines can be considered a field of Ark-neighbours intelligence since the calculated-neighbours viewed as squares of building in order to influence Personal computers to find out how one can carry on more brilliantly in one way or any another which is summing up despite of simply putting away and trying to do the recovering of information in things just like the database framework will accomplish.
Scikit-learn is a kind free library of learning of machine for the Python language. It always tends to highlights the different calculations like help vector machine, irregular woodlands, and k-neighbours, and it likewise underpins the numerical of Python and the libraries that are logical just like the SciPy and NumPy.
What is the machine learning?
Abnormal state definition: semi-computerized extraction of learning from information. Begins with information: You require information to correct bits of knowledge from it-
- Learning from information: Starts with an inquiry that may be liable utilizing information
- Robotized extraction: A PC gives the knowledge
- Semi-robotized: Requires many brilliant choices by a human
Research-
When all is said in done, a learning issue which considers a lot of n data tests of the information and after which they attempts to foresee the properties of the obscure information. In case, you each and every example is in excess of a solitary in the number and, for instance, a passage that is known as multi-dimensional (also which is known as multivariate information), it is also said that it might have a few of the traits or the highlights.
Learning problems fall into a couple of the classes:
Managed learning, in which all the relevant information that accompanies the extra ascribes which we need for anticipation. This concern can be any of the below mentioned:
- order: tests have a particular place where with at least any of the two classes and in which we need or tend to achieve gain from the effectively known information or data on how the anticipation the class of information that is unlabelled. In a case which is of a characterization concern can also be written by acknowledgment of hand digit, where the focus is in order to allot each and every information vector which is one of a limited number of that is related to discrete classes.
- relapse: In case, you the ideal yield who comprises of the minimum one factor that is persistent, that particular thing is called relapse. A case that can be considered of a relapse concern can either be the forecast in case of the length of a salmon.
Unsupervised learning, is a learning which is not supervised and which have the answers with itself. The pattern are supposed to be recognised in a manner that can be helpful to understand the data.
Machine Learning in Python turns into a breeze with the assistance of scikit-learn library. Scikit-learn is based on the Scientific Python process sfak which incorporates NumPy, SciPy, matplotlib and Pandas. It gives a wide scope of regulated and unsupervised machine learning calculations utilizing Python as we talked about above.
- Brisk model - Models (or calculations) in scikit-learn are executed with the accompanying centre capacities.
- fit - Trains a model.
- foresee - Predicts the yield for at least one cases utilizing the prepared model.
- predict_proba - Predicts the likelihood of all classes for at least one examples (arrangement) utilizing the prepared model.
- change - Preprocesses the preparation information (i.e standardize or scale the information).
The following is a basic managed grouping model utilizing scikit-learn. It utilizes the well-known iris dataset (gave as a toy dataset by scikit-learn), trains a choice tree classifier, makes forecasts on the preparation dataset itself and fares the choice tree as a picture to see how the calculation functions off camera.
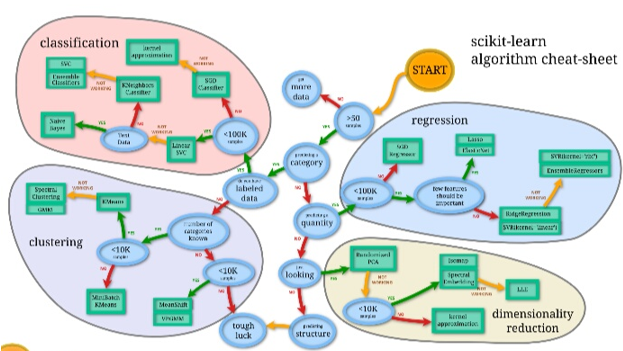
Figure 1: scikit-learn alogorithm
Methodology-
scikit-learn accompanies a couple of datasets that are of standard manner, for an instance, the digits and the iris datasets for the arrangement and the house of Boston costs the dataset in order to relapse.
Below accompanying, we start with Python translator and after that heap the digital algorithms and the iris. The notational tradition is the one that $ indicates the particular shell incite while the >>> signifies Python translator provoke:
A dataset is a word reference title that holds every information and some of the metadata that is about the relevant information. The information is given away in the part that is related to information, which can be the n_features and n_samples cluster. On account related to the regulated issue, either one reaction factors are given in the part named as .objective. More subtleties upon the distinctive datasets that can either be found under the devoted segment.
For example, on account of the dataset that are related to digits, digits.data tends to offer access related to the highlights that can either be utilized for the group and the tests of the digits:

also, digits.target tends to give the exact information, that is the number which is relating to each and every digit of the picture that we are trying to understand and learn:
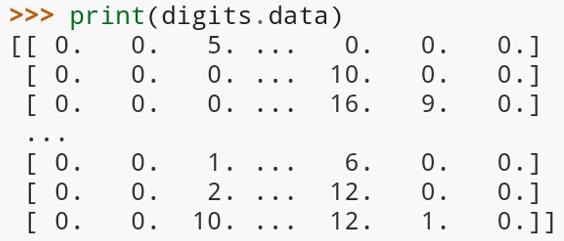
On account of the digits that are dataset, the assignment means to foresee, where a picture is given of which of the digit it tends to speaks to.
In the take in of scikit, an agenda of the estimator for characterization can be a Python object that run the plan predict(T) and fit(X, y).

A case of an predictor or the exact output maker is the class that is also named as sklearn.svm.SVC, which actualizes bolster grouping of vector. The estimator's constructor always takes the contentions as the parameters of model.
Presenting the scikit-learn estimator object
Each calculation is uncovered in scikit-learn through an ''Estimator'' object. For example a direct relapse is: sklearn.linear_model.LinearRegression

The clf (for classifier) estimator occurrence is first which is exactly fitted accurately to the related model; that also means that it must gain something from the related model. This gets finished by passing the preparation set directly to the fit technique. For the preparation set, we'll utilize every one of the pictures from our dataset, aside from the last picture, which we'll hold for our foreseeing. We select the preparation set with the [:- 1] Python language structure, which creates another exhibit that contains everything except the last thing from digits.data:

Presently you can anticipate new qualities. For this situation, you'll foresee utilizing the last picture from digits.data. By anticipating, you'll decide the picture from the preparation set that best matches the last picture.
Evaluation and Conclusion
The fate of planet Earth is Artificial Intelligence/Machine Learning. Any individual who does not comprehend it will before long wind up left behind. Awakening in this world brimming with advancement feels increasingly more like enchantment. There are numerous sorts of usage and methods to complete Artificial Intelligence and Machine Learning to tackle constant issues, out of which Supervised Learning is a standout amongst the most utilized methodologies.
In directed learning, we begin with bringing in dataset containing preparing characteristics and the objective traits. The Supervised Learning calculation will take in the connection between preparing precedents and their related target factors and apply that scholarly relationship to order completely new contributions (without targets).
A library that can be used to run, perform and execute some machine learning techniques in Python. It is also an library which is also open source and which is BSD authorised and can also be used in different settings, empowering scholastic and business purpose. It gives the scope related to unsupervised and supervised learning calculations that too in Python language. This learn comprises well known libraries and calculations.
Aside that, it also contains the below mentioned libraries:
- Matplotlib
- SciPy (Scientific Python)
- NumPy
This report has been done on Machine Learning where python has been used for the coding part and the report is based on scikit. NumPy and Pandas has been implement which are the libraries of python which are supposed to be implemented before doing anything with the Machine Learning in scikit.
Python Coding

The above mentioned is the coding in python for machine learning. While coding in python, some modules and libraries are supposed to be installed so that the data and the code can run effectively and give the desired output.
Scikit is written in Python (its majority) and a portion of its center calculations are written in Cython for surprisingly better execution.
Scikit-learn is utilized to assemble models and it isn't prescribed to utilize it for perusing, controlling and outlining information as there are better systems accessible for the reason.
It is open source and discharged under BSD permit.
Install Scikit Learn
Scikit expect you have a running Python 2.7 or above stage with NumPY (1.8.2 or more) and SciPY (0.13.3 or more) bundles on your gadget. When we have these bundles introduced we can continue with the installation.
For pip installation, run the below code in the terminal:
pip install scikit-learn - In the event that you like conda, you can likewise utilize the conda for bundle establishment, run the accompanying direction:
- conda install scikit-learn
Using Scikit-Learn- When you are finished with the installation, you can utilize scikit-learn effortlessly in your Python code by bringing in it as:
References-
Reddy Raamana, P. and C. Strother, S. (2017). Python class defining a machine learning dataset ensuring key-based correspondence and maintaining integrity. The Journal of Open Source Software, 2(17),
pp.34-67.
Lakshmi, J. (2018). Machine learning techniques using python for data analysis in performance evaluation. International Journal of Intelligent Systems Technologies and Applications, 17(1/2), p.3.
Iosifidis, A. (2015). Extreme learning machine based supervised subspace learning. Neurocomputing, 167(4), pp.158-164.
Zhang, Z. (2008). Mining relational data from text: From strictly supervised to weakly supervised learning. Information Systems, 33(3), pp.300-314.
Elghazel, H. and Aussem, A. (2013). Unsupervised feature selection with ensemble learning. Machine Learning, 98(1-2), pp.157-180.
Hughes, A. and Reeves, M. (2015). Scikit-spectra: Explorative Spectroscopy in Python. Journal of Open Research Software, 3(5), pp.234-567.
